社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
采用的是B+Tree
文件系统采用的是B-Tree
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。这样的话,索引查找过程中就要产生磁盘I/O的消耗,所以评价一个索引的优劣的重要指标就是I/O的操作次数。
I/O的操作次数与数的高度有关。数的高度O(h)=O(logdN)。由此可见d越大索引的性能就越好。相对于B-Tree而言,B+Tree内节点去掉了data域,因此可以拥有更大出度,故使用B+Tree。
MySQL中,索引属于存储引擎级别的概念,不同的存储索引对索引的实现方式是不同的。
MyISAM索引实现
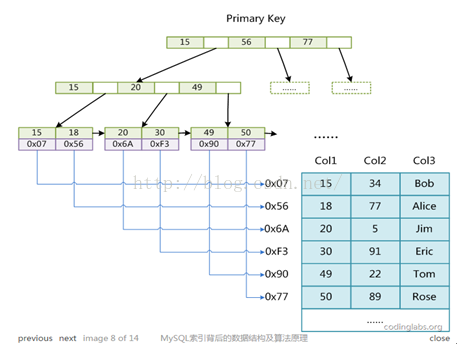
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。
l MyISAM的索引文件仅仅保存数据记录的地址。在MyISAM中,主索引和辅助索引在结构上没有区别。
l MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
InnoDB索引实现
InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同
1) MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。
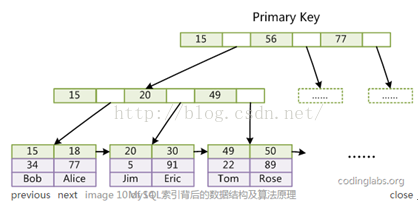
InnoDB的数据文件本身就是索引文件,即数据文件本身就是按B+Tree组织的一个索引结构,叶子节点data保存了完整的数据记录。
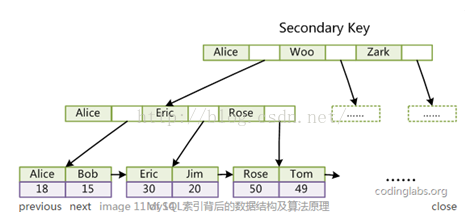
2) InnoDB的辅助索引data域存储相应记录主键的值而不是地址。
聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
1) 为查询缓存优化查询:即才有SQL模板,通过参数传递条件。
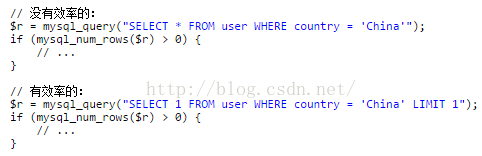
2) 当只要一行数据时使用LIMIT 1:MySQL数据库引擎会在找到一条数据后停止搜索,而不是继续往后查少下一条符合记录的数据
3) 使用EXPLINE关键字查看SQL语句
4) 为索引字段建索引:如果在表中,有某个字段你总要会经常用来做搜索,那么,为其建立索引。
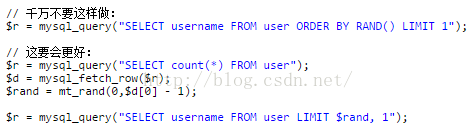
5) 不使用ORDER BY RAND():
打乱返回的数据行?随机挑一个数据
6) 避免使用SELECT *:
从数据库里读出越多的数据,那么查询就会变得越慢。并且,如果你的数据库服务器和WEB服务器是两台独立的服务器的话,这还会增加网络传输的负载。
即:需要什么取什么。
7) 拆分大的DELETE或INSERT语句:
8) 选择正确的存储索引:
在 MySQL 中有两个存储引擎 MyISAM 和 InnoDB,每个引擎都有利有弊。
MyISAM:适合于一些需要大量查询的应用,但其对于有大量写操作并不是很好。
InnoDB:写操作比较优秀,他支持“行锁”,并支持事务。
9) 对索引的优化
a) 越小的数据类型通常更好:越小的数据类型通常在磁盘、内存和CPU缓存中都需要更少的空间,处理起来更快。
b) 简单的数据类型更好:整型数据比起字符,处理开销更小,因为字符串的比较更复杂。
c) 尽量避免NULL:应该指定列为NOT NULL,除非你想存储NULL。在MySQL中,含有空值的列很难进行查询优化,因为它们使得索引、索引的统计信息以及比较运算更加复杂。应该用0、一个特殊的值或者一个空串代替空值。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!