社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
本文基于golang 1.14 对sync.Pool进行分析;
参考 Golang 的 sync.Pool设计思路与原理,这篇文章基于1.12版本对golang的sync.Pool实现原理进行了分析。关于sync.Pool的使用场景、基本概念的理解可以参考前面的文章。
在1.12中sync.Pool的设计思路简单总结一下:
1.12 sync.pool的源码,可以发现sync.pool里会有各种的锁逻辑,从自己的shared拿数据加锁。getSlow()偷其他P缓存,也是需要给每个p加锁。put归还缓存的时候,还是会mutex加一次锁。
go mutex锁的实现原理简单说,他开始也是atomic cas自旋,默认是4次尝试,当还没有拿到锁的时候进行waitqueue gopack休眠调度处理,等待其他协程释放锁时进行goready调度唤醒。
Go 1.13之后,Go 团队对sync.Pool的锁竞争这块进行了很多优化,这里还改变了shared的数据结构,以前的版本用切片做缓存,现在换成了poolChain双端链表。这个双端链表的设计很有意思,你看sync.pool源代码会发现跟redis quicklist相似,都是链表加数组的设计。
type Pool struct {
noCopy noCopy
local unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocal
localSize uintptr // size of the local array
victim unsafe.Pointer // local from previous cycle
victimSize uintptr // size of victims array
// New optionally specifies a function to generate
// a value when Get would otherwise return nil.
// It may not be changed concurrently with calls to Get.
New func() interface{}
}
// Local per-P Pool appendix.
type poolLocalInternal struct {
private interface{} // Can be used only by the respective P.
shared poolChain // Local P can pushHead/popHead; any P can popTail.
}
type poolLocal struct {
poolLocalInternal
// Prevents false sharing on widespread platforms with
// 128 mod (cache line size) = 0 .
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}
Pool.local 实际上是一个类型 [P]poolLocal 数组,数组长度是调度器中P的数量,也就是说每一个P有自己独立的poolLocal。通过P.id来获取每个P自己独立的poolLocal。在poolLocal中有一个poolChain。
这里我们先忽略其余的机构,重点关注poolLocalInternal.shared 这个字段。poolChain是一个双端队列链,缓存对象。 1.12版本中对于这个字段的并发安全访问是通过mutex加锁实现的;1.14优化后通过poolChain(无锁化)实现的。
这里我们先重点分析一下poolChain 是怎么实现并发无锁编程的。
type poolChain struct {
// head is the poolDequeue to push to. This is only accessed
// by the producer, so doesn't need to be synchronized.
head *poolChainElt
// tail is the poolDequeue to popTail from. This is accessed
// by consumers, so reads and writes must be atomic.
tail *poolChainElt
}
type poolChainElt struct {
poolDequeue
// next and prev link to the adjacent poolChainElts in this
// poolChain.
//
// next is written atomically by the producer and read
// atomically by the consumer. It only transitions from nil to
// non-nil.
//
// prev is written atomically by the consumer and read
// atomically by the producer. It only transitions from
// non-nil to nil.
next, prev *poolChainElt
}
poolChain是一个动态大小的双向链接列表的双端队列。每个出站队列的大小是前一个队列的两倍。也就是说poolChain里面每个元素poolChainElt都是一个双端队列。
head指向的poolChainElt,是用于Producer去Push元素的,不需要做同步处理。
tail指向的poolChainElt,是用于Consumer从tail去pop元素的,这里的读写需要保证原子性。
简单来说,poolChain是一个单Producer,多Consumer并发访问的双端队列链。
对于poolChain中的每一个双端队列 poolChainElt,包含了双端队列实体poolDequeue 一起前后链接的指针。
poolChain 主要方法有:
popHead() (interface{}, bool);
pushHead(val interface{})
popTail() (interface{}, bool)
popHead和pushHead函数是给Producer调用的;popTail是给Consumer并发调用的。
前面我们说了,poolChain的head 指针的操作是单Producer的。
func (c *poolChain) popHead() (interface{}, bool) {
d := c.head
for d != nil {
if val, ok := d.popHead(); ok {
return val, ok
}
// There may still be unconsumed elements in the
// previous dequeue, so try backing up.
d = loadPoolChainElt(&d.prev)
}
return nil, false
}
poolChain要求,popHead函数只能被Producer调用。看一下逻辑:
poolDequeue中调用popHead函数。注意这里poolDequeue的popHead函数和poolChain的popHead函数并不一样。poolDequeue是一个固定size的ring buffer。func (c *poolChain) pushHead(val interface{}) {
d := c.head
if d == nil {
// Initialize the chain.
const initSize = 8 // Must be a power of 2
d = new(poolChainElt)
d.vals = make([]eface, initSize)
c.head = d
storePoolChainElt(&c.tail, d)
}
if d.pushHead(val) {
return
}
// The current dequeue is full. Allocate a new one of twice
// the size.
newSize := len(d.vals) * 2
if newSize >= dequeueLimit {
// Can't make it any bigger.
newSize = dequeueLimit
}
d2 := &poolChainElt{prev: d}
d2.vals = make([]eface, newSize)
c.head = d2
storePoolChainElt(&d.next, d2)
d2.pushHead(val)
}
poolChain要求,pushHead函数同样只能被Producer调用。看一下逻辑:
poolChainElt 节点,作为head, 当然也是tail。poolChainElt 其实也是固定size的双端队列poolDequeue,size必须是2的n次幂。poolDequeue的pushHead函数将 val push进head的双端队列poolDequeue。这里需要注意一点的是head其实是指向最后chain中最后一个结点(poolDequeue),chain执行push操作是往最后一个节点push。 所以这里的head的语义不是针对链表结构,而是针对队列结构。
func (c *poolChain) popTail() (interface{}, bool) {
d := loadPoolChainElt(&c.tail)
if d == nil {
return nil, false
}
for {
// It's important that we load the next pointer
// *before* popping the tail. In general, d may be
// transiently empty, but if next is non-nil before
// the pop and the pop fails, then d is permanently
// empty, which is the only condition under which it's
// safe to drop d from the chain.
d2 := loadPoolChainElt(&d.next)
if val, ok := d.popTail(); ok {
return val, ok
}
if d2 == nil {
// This is the only dequeue. It's empty right
// now, but could be pushed to in the future.
return nil, false
}
// The tail of the chain has been drained, so move on
// to the next dequeue. Try to drop it from the chain
// so the next pop doesn't have to look at the empty
// dequeue again.
if atomic.CompareAndSwapPointer((*unsafe.Pointer)(unsafe.Pointer(&c.tail)), unsafe.Pointer(d), unsafe.Pointer(d2)) {
// We won the race. Clear the prev pointer so
// the garbage collector can collect the empty
// dequeue and so popHead doesn't back up
// further than necessary.
storePoolChainElt(&d2.prev, nil)
}
d = d2
}
}
poolChain要求,popTail函数能被任何P调用,也就是所有的P都是Consumer。这里总结下,当前G所对应的P在Pool里面是Producer角色,任何P都是Consumer角色。
popTail函数是并发调用的,所以需要特别注意。
poolDequeue);上面的流程是典型的的无锁并发编程。
poolChain中每一个结点都是一个双端队列poolDequeue。
poolDequeue是一个无锁的、固定size的、单Producer、多Consumer的deque。只有一个Producer可以从head去push或则pop;多个Consumer可以从tail去pop。
type poolDequeue struct {
// 用高32位和低32位分别表示head和tail
// head是下一个fill的slot的index;
// tail是deque中最老的一个元素的index
// 队列中有效元素是[tail, head)
headTail uint64
vals []eface
}
type eface struct {
typ, val unsafe.Pointer
}
这里通过一个字段 headTail 来表示head和tail的index。headTail是8个字节64位。
vals是一个固定size的slice,其实也就是一个 ring buffer,size必须是2的次幂(为了做位运算);
一个字段 headTail 来表示head和tail的index,所以需要有具体的pack和unpack逻辑:
const dequeueBits = 32
func (d *poolDequeue) unpack(ptrs uint64) (head, tail uint32) {
const mask = 1<<dequeueBits - 1
head = uint32((ptrs >> dequeueBits) & mask)
tail = uint32(ptrs & mask)
return
}
func (d *poolDequeue) pack(head, tail uint32) uint64 {
const mask = 1<<dequeueBits - 1
return (uint64(head) << dequeueBits) |
uint64(tail&mask)
}
pack:
unpack:
pushHead 将val push到head指向的位置,如果deque满了,就返回false。
func (d *poolDequeue) pushHead(val interface{}) bool {
ptrs := atomic.LoadUint64(&d.headTail)
head, tail := d.unpack(ptrs)
if (tail+uint32(len(d.vals)))&(1<<dequeueBits-1) == head {
// Queue is full.
return false
}
slot := &d.vals[head&uint32(len(d.vals)-1)]
// Check if the head slot has been released by popTail.
typ := atomic.LoadPointer(&slot.typ)
if typ != nil {
// Another goroutine is still cleaning up the tail, so
// the queue is actually still full.
return false
}
// The head slot is free, so we own it.
if val == nil {
val = dequeueNil(nil)
}
*(*interface{})(unsafe.Pointer(slot)) = val
// Increment head. This passes ownership of slot to popTail
// and acts as a store barrier for writing the slot.
atomic.AddUint64(&d.headTail, 1<<dequeueBits)
return true
}
主要逻辑:
需要注意的是,pushHead不是并发安全的,只能有一个Producer去执行;只有slot的的type指针为空时候slot才是空。
popHead 将head指向的前一个位置弹出,如果deque是空,就返回false。
func (d *poolDequeue) popHead() (interface{}, bool) {
var slot *eface
for {
ptrs := atomic.LoadUint64(&d.headTail)
head, tail := d.unpack(ptrs)
if tail == head {
// Queue is empty.
return nil, false
}
// Confirm tail and decrement head. We do this before
// reading the value to take back ownership of this
// slot.
head--
ptrs2 := d.pack(head, tail)
if atomic.CompareAndSwapUint64(&d.headTail, ptrs, ptrs2) {
// We successfully took back slot.
slot = &d.vals[head&uint32(len(d.vals)-1)]
break
}
}
val := *(*interface{})(unsafe.Pointer(slot))
if val == dequeueNil(nil) {
val = nil
}
// Zero the slot. Unlike popTail, this isn't racing with
// pushHead, so we don't need to be careful here.
*slot = eface{}
return val, true
}
主要逻辑:
poolDequeue.headTail然后unpack拿到head和tailpoolDequeue.headTail,atomic.CompareAndSwapUint64(&d.headTail, ptrs, ptrs2),这个函数是可以被Consumer并发访问的。
func (d *poolDequeue) popTail() (interface{}, bool) {
var slot *eface
for {
ptrs := atomic.LoadUint64(&d.headTail)
head, tail := d.unpack(ptrs)
if tail == head {
// Queue is empty.
return nil, false
}
// Confirm head and tail (for our speculative check
// above) and increment tail. If this succeeds, then
// we own the slot at tail.
ptrs2 := d.pack(head, tail+1)
if atomic.CompareAndSwapUint64(&d.headTail, ptrs, ptrs2) {
// Success.
slot = &d.vals[tail&uint32(len(d.vals)-1)]
break
}
}
// We now own slot.
val := *(*interface{})(unsafe.Pointer(slot))
if val == dequeueNil(nil) {
val = nil
}
// Tell pushHead that we're done with this slot. Zeroing the
// slot is also important so we don't leave behind references
// that could keep this object live longer than necessary.
//
// We write to val first and then publish that we're done with
// this slot by atomically writing to typ.
slot.val = nil
atomic.StorePointer(&slot.typ, nil)
// At this point pushHead owns the slot.
return val, true
}
主要逻辑:
atomic.CompareAndSwapUint64(&d.headTail, ptrs, ptrs2); 如果更新成功,就拿到vals[tail]t的指针。如果失败就再次返回1的for循环。用一张图完整描述sync.Pool的数据结构: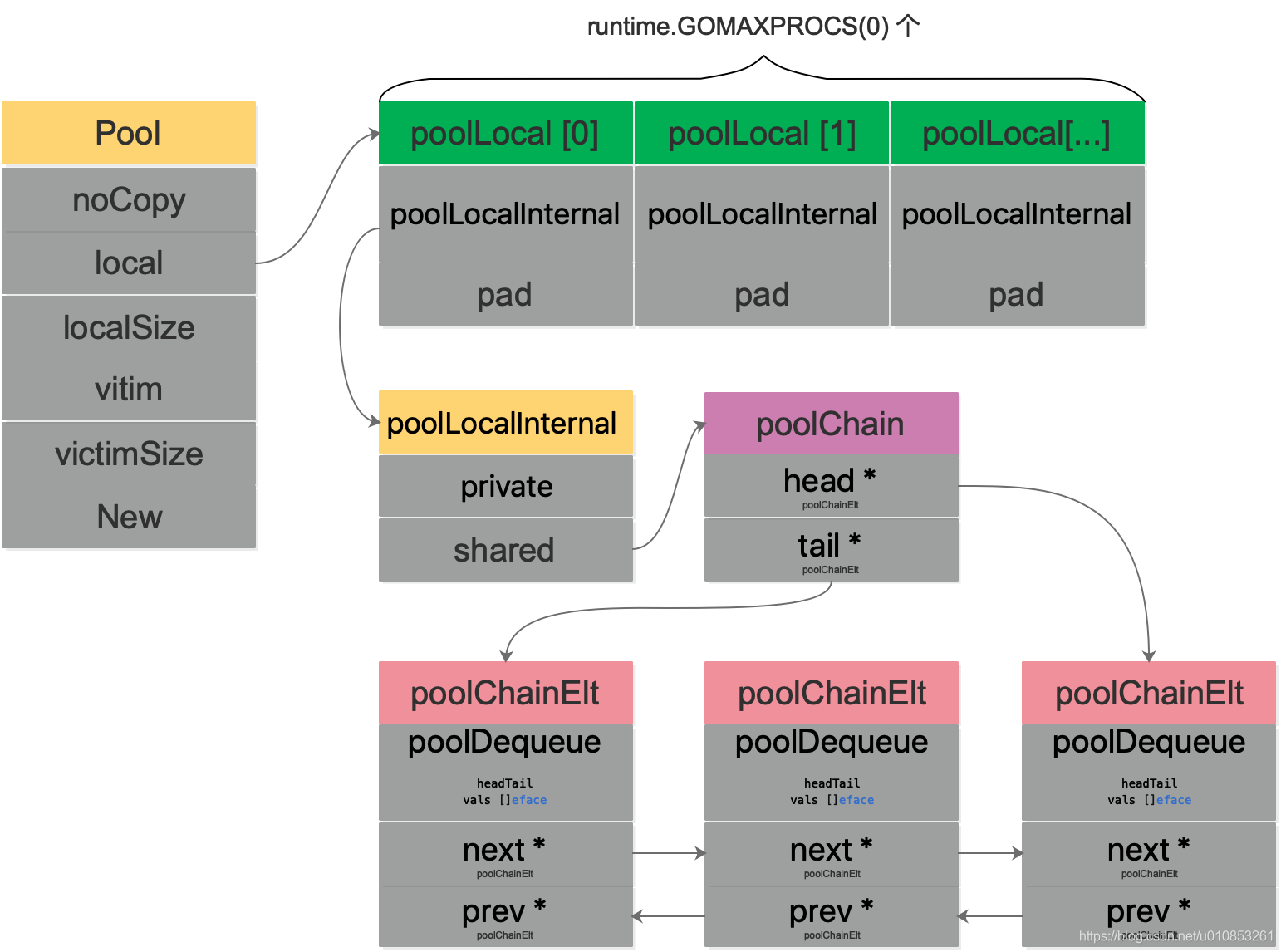
强调一点:
参考网上一张图来看更加清晰: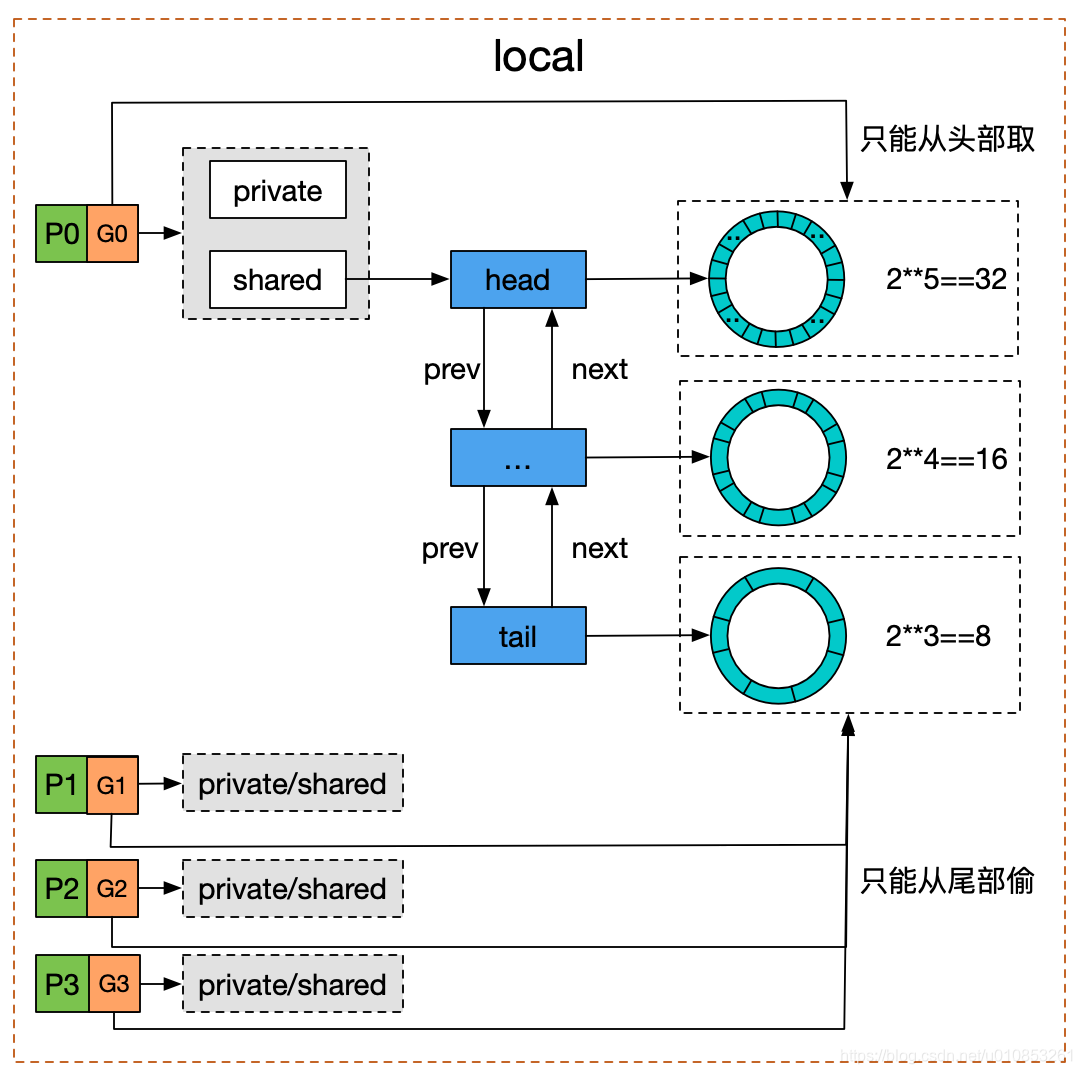
Pool 并没有直接使用 poolDequeue,因为它是fixed size的,而 Pool 的大小是没有限制的。因此,在 poolDequeue 之上包装了一下,变成了一个 poolChainElt 的双向链表,可以动态增长。
func (p *Pool) Put(x interface{}) {
if x == nil {
return
}
l, _ := p.pin()
if l.private == nil {
l.private = x
x = nil
}
if x != nil {
l.shared.pushHead(x)
}
runtime_procUnpin()
}
func (p *Pool) pin() (*poolLocal, int) {
pid := runtime_procPin()
// In pinSlow we store to local and then to localSize, here we load in opposite order.
// Since we've disabled preemption, GC cannot happen in between.
// Thus here we must observe local at least as large localSize.
// We can observe a newer/larger local, it is fine (we must observe its zero-initialized-ness).
s := atomic.LoadUintptr(&p.localSize) // load-acquire
l := p.local // load-consume
if uintptr(pid) < s {
return indexLocal(l, pid), pid
}
return p.pinSlow()
}
func (p *Pool) pinSlow() (*poolLocal, int) {
// Retry under the mutex.
// Can not lock the mutex while pinned.
runtime_procUnpin()
allPoolsMu.Lock()
defer allPoolsMu.Unlock()
pid := runtime_procPin()
// poolCleanup won't be called while we are pinned.
s := p.localSize
l := p.local
if uintptr(pid) < s {
return indexLocal(l, pid), pid
}
if p.local == nil {
allPools = append(allPools, p)
}
// If GOMAXPROCS changes between GCs, we re-allocate the array and lose the old one.
size := runtime.GOMAXPROCS(0)
local := make([]poolLocal, size)
atomic.StorePointer(&p.local, unsafe.Pointer(&local[0])) // store-release
atomic.StoreUintptr(&p.localSize, uintptr(size)) // store-release
return &local[pid], pid
}
Put函数主要逻辑:
p.pin() 函数,这个函数会将当前 goroutine与P绑定,并设置当前g不可被抢占(也就不会出现多个协程并发读写当前P上绑定的数据);p.pin() 函数里面还会check per P的[P]poolLocal数组是否发生了扩容(P 扩张)。pinSlow()来执行具体扩容。扩容获取一个调度器全局大锁allPoolsMu,然后根据当前最新的P的数量去执行新的扩容。这里的成本很高,所以尽可能避免手动增加P的数量。shared.pushHead(x) 塞到poolLocal里面的无锁双端队列的chain中。Put函数对于双端队列来说是作为一个Producer角色,所以这里的调用是无锁的。func (p *Pool) Get() interface{} {
l, pid := p.pin()
x := l.private
l.private = nil
if x == nil {
// Try to pop the head of the local shard. We prefer
// the head over the tail for temporal locality of
// reuse.
x, _ = l.shared.popHead()
if x == nil {
x = p.getSlow(pid)
}
}
runtime_procUnpin()
if x == nil && p.New != nil {
x = p.New()
}
return x
}
func (p *Pool) getSlow(pid int) interface{} {
// See the comment in pin regarding ordering of the loads.
size := atomic.LoadUintptr(&p
版权声明:本文来源CSDN,感谢博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/u010853261/article/details/106156091
站方申明:本站部分内容来自社区用户分享,若涉及侵权,请联系站方删除。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
