社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
Kafka: 是一个高吞吐低延迟的高并发,高性能消息中间件。配置良好的Kafka集群能够做到每秒几十万或者上百万的超高并发写入。
Kafka接收到数据的时候,都会往磁盘上去写
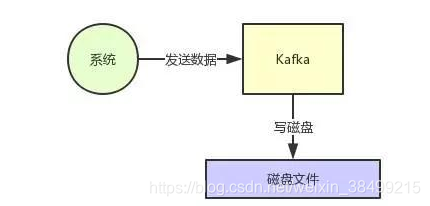
内存里面的缓存,是操作系统自己管理的缓存。
在写入磁盘文件的时候,可以直接写入到OS cache里。接下来由操作系统自己决定何时把cache里面的数据刷写到磁盘文件当中。
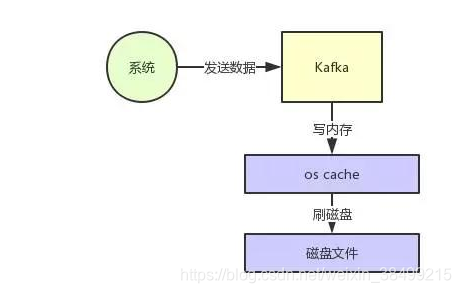
而且kafka写数据的时候,是以磁盘顺序写的方式来写的。
就是说写数据是按照追加文件末尾来写,而不是随机写的。
消费的本质是从磁盘文件读取某条数据然后发送到下游的消费者。
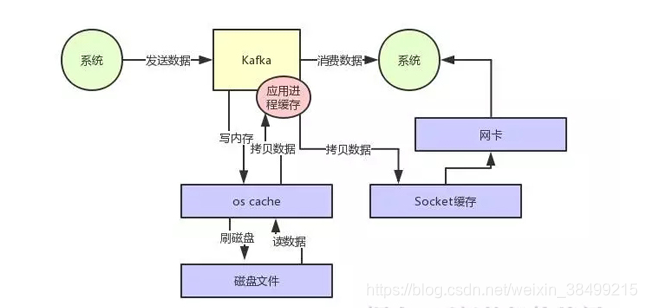 首先先判断数据是否在os cache,不在的话从磁盘文件中读取,放到cache当中.
首先先判断数据是否在os cache,不在的话从磁盘文件中读取,放到cache当中.
然后从操作系统的OS cache里拷贝数据到应用程序进程的缓存去,再从应用程序进程的缓存拷贝数据到操作系统里面的socket缓存里面。
再从socket提取数据发送到网卡。
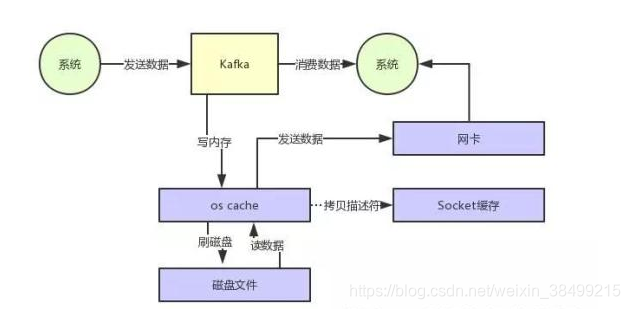
不需要把OS cache中的数据拷贝到应用缓存,再从应用缓存拷贝到socket缓存了。数据直接从os cache发送到网卡上去。
所以kafka大量的数据读写都是发生在OS CACHE当中的。
Kafka设计是把数据写入硬盘中,以此来换取更强大的存储能力。
我们经常说的硬盘IO速度慢,很大程度上是指随机IO,而如果是顺序IO的话,速度还是非常快的。
Sequence I/O: 600MB/s
Random I/O: 100KB/s
这一组数据是kafka官方给出的测试数据。
上文讲过,上游有写操作的时候,操作系统把数据写入PageCache,同时标记Page属性为Dirty.
当读操作发生的时候,先从PageCache中查找,如果发生缺页才进行磁盘调度。
为了进一步优化性能,kafka还会使用SendFile(零拷贝)技术。
传统的网络IO
1.OS从硬盘中把数据读到内核区的PageCache.
2.用户进程把数据从内核区copy到用户区。
3.用户进程再把数据写入到socket,数据流如内核区的socket Buffer中
4.OS再把数据从buffer中copy到网卡的copy中
其中涉及到4次系统调用,2次上下文切换。同一份数据会在内核和用户buffer之间重复拷贝。效率很低
零拷贝的思想就是把步骤2,3直接略去,直接在内核去完成数据拷贝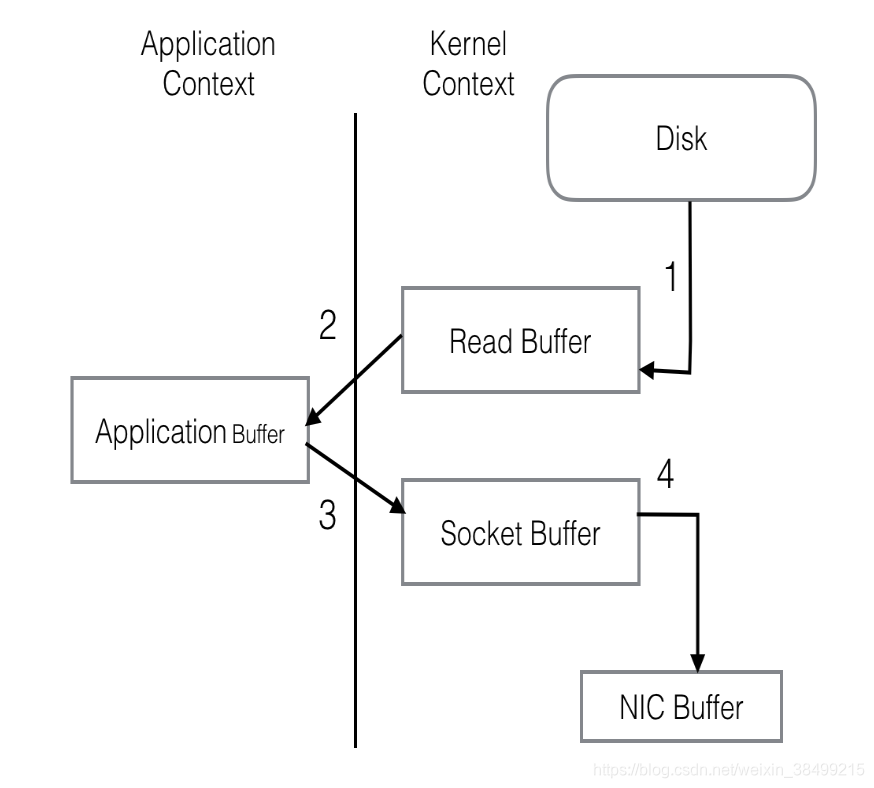 这样就可以把过程优化为如下图
这样就可以把过程优化为如下图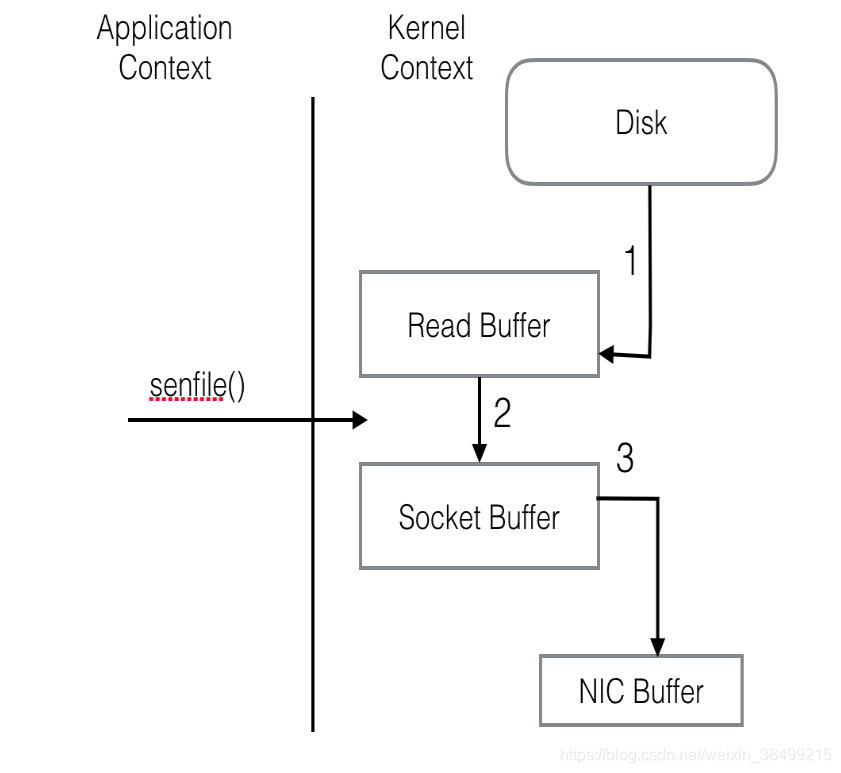
kafka调优
在磁盘测试中最关心的几个指标分别为:iops(每秒执行的IO次数)、bw(带宽,每秒的吞吐量)、lat(每次IO操作的延迟)
kafka性能与磁盘IO是紧密关联的
iops——写测试 dd if=/dev/zero of=./a.dat bs=8k count=1M oflag=direct
iops——读测试 dd if=./a.dat of=/dev/null bs=8k count=1M iflag=direct
bw——写测试 dd if=/dev/zero of=./a.dat bs=1M count=8k oflag=direct
bw——读测试 dd if=./a.dat of=/dev/null bs=1M count=8k iflag=direct
我实习的时候,遇到的问题是Kafka producer在ecs上的写入速度非常非常慢,初步怀疑是磁盘IO性能制约!
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
