社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
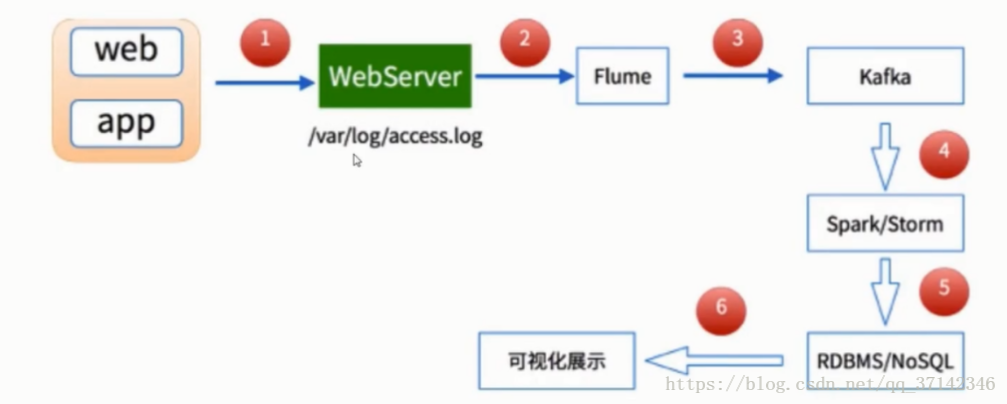
大数据实时流式数据处理是大数据应用中最为常见的场景,与我们的生活也息息相关,以手机流量实时统计来说,它总是能够实时的统计出用户的使用的流量,在第一时间通知用户流量的使用情况,并且最为人性化的为用户提供各种优惠的方案,如果采用离线处理,那么等到用户流量超标了才通知用户,这样会使得用户体验满意度降低,这也是这几年大数据实时流处理的进步,淡然还有很多应用场景。因此Spark Streaming应用而生,不过对于实时我们应该准确理解,需要明白的一点是Spark Streaming不是真正的实时处理,更应该成为准实时,因为它有延迟,而真正的实时处理Storm更为适合,最为典型场景的是淘宝双十一大屏幕上盈利额度统计,在一般实时度要求不太严格的情况下,Spark Streaming+Flume+Kafka是大数据准实时数据采集的最为可靠并且也是最常用的方案,大数据实时流式数据采集的流程图如下所示:
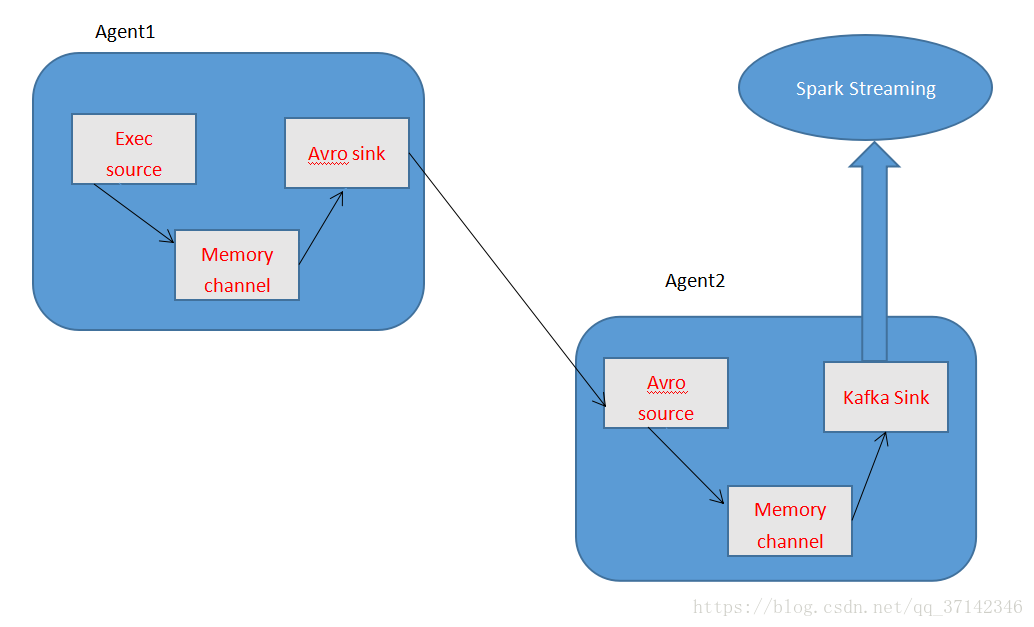
在本篇文章中使用Flume+Kafka+Spark Streaming具体实现大数据实时流式数据采集的架构图如下:
转发请标明原文地址:原文地址
对Flume,Spark Streaming,Kafka的配置如有任何问题请参考笔者前面的文章:
开发环境、工具:
下面我们就开始进行实战配置:
Flume文件配置
首先创建两个配置文件分别来启动两个Agent。
exec-memory-avro.conf:
# The configuration file needs to define the sources,
# the channels and the sinks.
# Sources, channels and sinks are defined per agent,
# in this case called 'agent'
f1.sources = r1
f1.channels = c1
f1.sinks = k1
#define sources
f1.sources.r1.type = exec
f1.sources.r1.command =tail -f /opt/datas/flume.log
#define channels
f1.channels.c1.type = memory
f1.channels.c1.capacity = 1000
f1.channels.c1.transactionCapacity = 100
#define sink
f1.sinks.k1.type = avro
f1.sinks.k1.hostname = hadoop-senior.shinelon.com
f1.sinks.k1.port =44444
#bind sources and sink to channel
f1.sources.r1.channels = c1
f1.sinks.k1.channel = c1
avro-memory-kafka.conf:
# The configuration file needs to define the sources,
# the channels and the sinks.
# Sources, channels and sinks are defined per agent,
# in this case called 'agent'
f2.sources = r2
f2.channels = c2
f2.sinks = k2
#define sources
f2.sources.r2.type = avro
f2.sources.r2.bind =hadoop-senior.shinelon.com
f2.sources.r2.port =44444
#define channels
f2.channels.c2.type = memory
f2.channels.c2.capacity = 1000
f2.channels.c2.transactionCapacity = 100
#define sink
f2.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink
f2.sinks.k2.brokerList = hadoop-senior.shinelon.com:9092
f2.sinks.k2.topic =testSpark
f2.sinks.k2.batchSize=4
f2.sinks.k2.requiredAcks=1
#bind sources and sink to channel
f2.sources.r2.channels = c2
f2.sinks.k2.channel = c2
上面的配置文件关键需要注意kafka的配置,如有不懂也可参考Flume官方文档的说明。
接着我们启动Flume,记得首先启动avro-memory-kafka.conf的Agent:
bin/flume-ng agent
--conf conf --name f2
--conf-file conf/avro-memory-kafka.conf
-Dflume.root.logger=DEBUG,console
bin/flume-ng agent
--conf conf --name f1
--conf-file conf/exec-memory-avro.conf
-Dflume.root.logger=DEBUG,console
Kafka配置
注意:在启动Kafka之前要启动Zookeeper
下面就是kafka的配置:
server.properties:
主要注意下面几个参数的配置,其他的参数默认就好。
broker.id=0
port=9092
host.name=hadoop-senior.shinelon.com
log.dirs=/opt/cdh-5.3.6/kafka_2.10-0.8.2.1/kafka_logs
zookeeper.connect=hadoop-senior.shinelon.com:2181
启动kafka(以后台进程的方式启动):
bin/kafka-server-start.sh -daemon config/server.properties &
创建topic:
注意topic的名称,需要与上面Flume中的配置一致,也要与下面Spark Streaming中设置的一致。
bin/kafka-topics.sh --create --zookeeper hadoop-senior.shinelon.com:2181 --replication-factor 1 --partitions 1 --
topic testSpark
Spark Streaming配置
首先需要导入Spark Streaming所需要的jar包并且启动Spark:
bin/spark-shell --master local[2] --jars
/opt/cdh-5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externallibs/spark-streaming-kafka_2.10-1.3.0.jar,/opt/cdh-5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externallibs/kafka_2.10-0.8.2.1.jar,/opt/cdh-5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externallibs/kafka-clients-0.8.2.1.jar,/opt/cdh-5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externallibs/zkclient-0.3.jar,/opt/cdh-5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externallibs/metrics-core-2.2.0.jar
接着编写脚本启动Spark Streaming,这个脚本使用Spark Streaming实现wordCount功能,代码如下:
SparkWordCount.scala:
import java.util.HashMap
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.kafka._
val ssc = new StreamingContext(sc, Seconds(5))
val topicMap = Map("testSpark" -> 1)
// read data
val lines = KafkaUtils.createStream(ssc, "hadoop-senior.shinelon.com:2181", "testWordCountGroup", topicMap).map(_._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
执行上面的脚本就启动了Spark Streaming(对应脚本的路径):
:load /opt/spark/SparkWordCount.scala
这时就启动好了Spark Streaming,至此所有的配置已经完成,所有的服务器也已经启动,现在进行测试,在上面Flume中exec中设置的文件中写入数据:
[shinelon@hadoop-senior datas]$ echo hadoop spark hadoop saprk hadoop>>flume.log
[shinelon@hadoop-senior datas]$ echo hadoop spark hadoop saprk hadoop>>flume.log
[shinelon@hadoop-senior datas]$ echo hadoop spark hadoop saprk hadoop>>flume.log
[shinelon@hadoop-senior datas]$ echo hadoop spark hadoop saprk hadoop>>flume.log
[shinelon@hadoop-senior datas]$ echo hadoop spark hadoop saprk hadoop>>flume.log
[shinelon@hadoop-senior datas]$ echo hadoop spark hadoop saprk hadoop>>flume.log
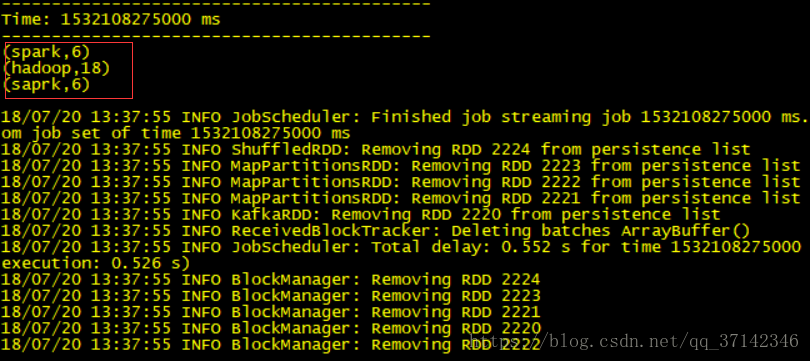
可以看见在Spark Streaming中采集到了数据并且进行了计数:
至此,我们就完成了Flume+Kafka+Spark Streaming的整合实现大数据实时流式数据采集,如有任何问题欢迎留言讨论。
如果你想和我一起探讨学习,共同进步,欢迎加群:
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!