社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
简介
性质
构建
可以使用链表来实现,每个字符串都是一个链表。
应用
游戏屏蔽字替换
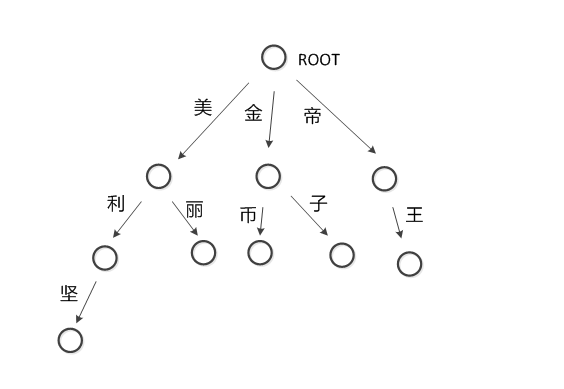
问题:假设上图就是游戏屏蔽字,有字符串“你来自美利坚帝国吗?”。需要将敏感词转换为*。
用3个指针来进行操作,分别是p1,p2,p3。p1指向屏蔽字树,p2和p3指向需要检测的字符串
伪代码
func SensitiveTransform(word string) string {
t := []rune(strings.ToLower(word)) // 转换为unicode数组
p1 := tree.GetRoot() // p1指向树的根节点
p2 := t[0] // p2是过滤内容的第一个字符
var p2Index, p3Index int // p2的位置,p3的位置,默认是过滤内容的第一个字符的位置
newWord := word // 过滤后的字符串
// p3指向最后一个字符,则结束
for ; p3Index < len(t); {
// 遍历从p3开始到结尾的字符串
for i := p3Index; i < len(t); i++ {
char := t[i]
if !p1.Contains(p2) {
// 如果p2不是p1子节点,说明以p3开始的内容不需要屏蔽,p3指向下一个位置,p2指向p3,并将p1重置到root节点,终止循环
p2Index = p3Index + 1
p3Index = p3Index + 1
if p2Index < len(t) {
p2 = t[p2Index]
}
p1 = tree.GetRoot()
break
} else {
// 如果p2是p1的子节点,p1节点移动到p2内容对应的节点上,p2移动到下个位置
// 获取p1的子节点
p1 = p1.GetChildNode(char)
// 移动P2到下个位置
p2Index = p2Index + 1
if p2Index < len(t) {
p2 = t[p2Index]
}
if !p1.HasChild() {
// p1没有子节点,树的某条路径遍历完了,说明字符串中含有敏感词
p1 = tree.GetRoot()
// 将敏感词替换成*
temp := []rune(newWord)
newWord = string(temp[:p3Index]) + strings.Repeat("*", p2Index-p3Index) + string(temp[p2Index:])
// p3移动到p2的位置
p3Index = p2Index
}
}
}
}
return newWord
}
时间复杂度
实现
基于Golang的实现:https://github.com/MaxwellBackend/Algorithm/tree/master/trie
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
