社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
iOS行业不好混了,公司现在基本没什么事做了。无聊之中,随便搞搞,以前从事C++的时候用过Python,于是心血来潮,试着写下小爬虫,爬取百度上的图片。
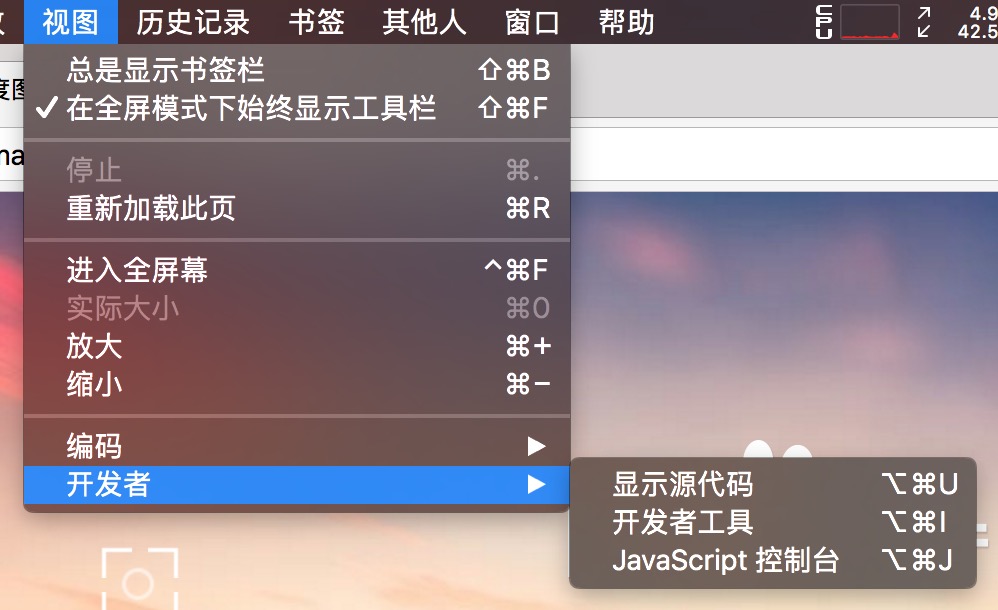
用Chrome打开百度图片,随意搜索一个关键字,再打开『开发者工具』,如图所示:
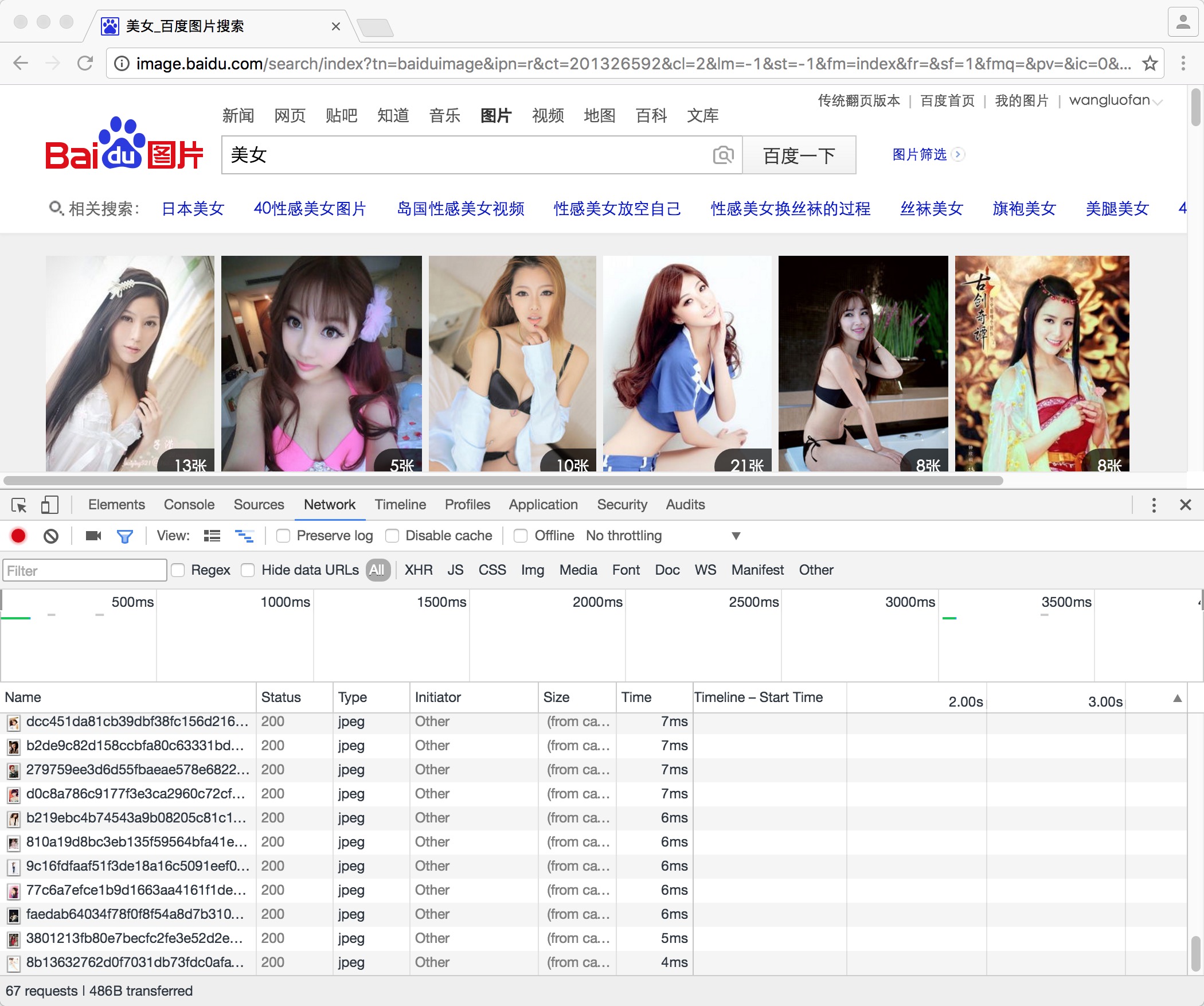
打开后的效果,如图所示:
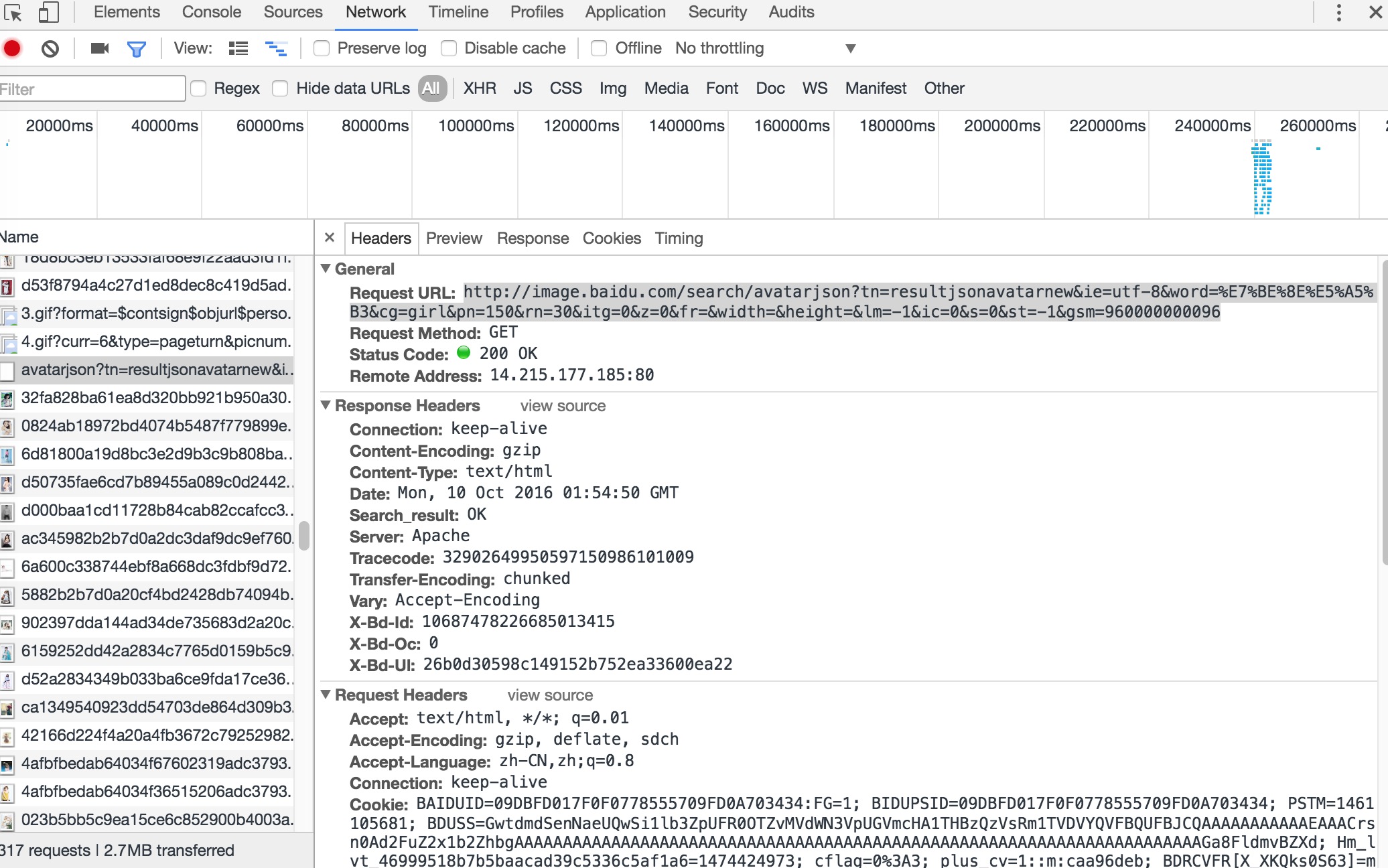
然后再次点击搜索,切换到『Network』选项卡,可以看到该页面发出的所有请求,找接口的主要目的就是找到返回图片列表的请求。我们可以找到如下请求:
经过验证,该接口返回的JSON数据,正是图片列表,接口地址:
http://image.baidu.com/search/avatarjson?tn=resultjsonavatarnew&ie=utf-8&word=%E7%BE%8E%E5%A5%B3&cg=girl&pn=150&rn=30&itg=0&z=0&fr=&width=&height=&lm=-1&ic=0&s=0&st=-1&gsm=960000000096该爬虫使用Python编写,所以电脑上需要安装有Python环境,如果使用的是*nix系统,一般都是自带Python的,该爬虫还使用了requests模块,该模块并不是Python自带的,百度上有很多关于requests库安装和使用的文章,请参考:
requests库的安装
使用requests库的优点在其中也有提及。
到这里,我们开始编写代码了,不过编写代码之前,还是要选一款适合自己的编辑器,Python自带的Idle本来我觉得不好,我使用了Vim,但是发现缩进不正确,又懒得去改,所以还是使用了Idle,其实还有很多,比如Sublime Text, UltraEdit等等都很好用。
万事俱备,只欠东风,开始编写代码。首先约定输入参数的形式,如下
python ImgSearch.py [Keyword] [DownloadDir] [Pages=1]包括要搜索的关键词Keyword,图片的下载目录[DownloadDir],还有要下载的页数[Pages],默认为1,编码的第一步当然是要检查输入参数的,代码如下所示:
def CheckArgs():
if(len(sys.argv) < 3):
print 'Usage: python ImgSearch.py [Keyword] [DownloadDir] [Pages=1]';
return False;
return True;该段只检查了参数个数,因为第一个参数是脚本名字,所以如果参数小于3个,证明输入有误,并告知用户使用方法。
输入正常之后,就可以开始搜索图片了。
首先上代码
def Search():
params = {
'tn' : 'resultjsonavatarnew',
'ie' : 'utf-8',
'cg' : '',
'itg' : '',
'z' : '0',
'fr' : '',
'width' : '',
'height' : '',
'lm' : '-1',
'ic' : '0',
's' : '0',
'word' : sys.argv[1],
'st' : '-1',
'gsm' : '',
'rn' : '30'
};
if(len(sys.argv) == 4):
pages = int(sys.argv[3]);
else:
pages = 1;
for i in range(0, pages):
params['pn'] = '%d' % i;
Request(params);
return ;其实都不懂百度图片中请求的参数的意思,不过经过验证,有一些参数是可以去掉的,有些能去掉的参数我也保留了。所以上述参数并不是需要全部传入。目前为止,pn参数代表的应该是页数,rn代表的应该是每页多少张图片,word参数自然是关键词,知道这些就足够了。之后就是发送请求,请求JSON数据了。
如代码所示:
def Request(param):
searchurl = 'http://image.baidu.com/search/avatarjson';
response = requests.get(searchurl, params=param);
json = response.json()['imgs'];
for i in range(0, len(json)):
filename = os.path.split(json[i]['objURL'])[1];
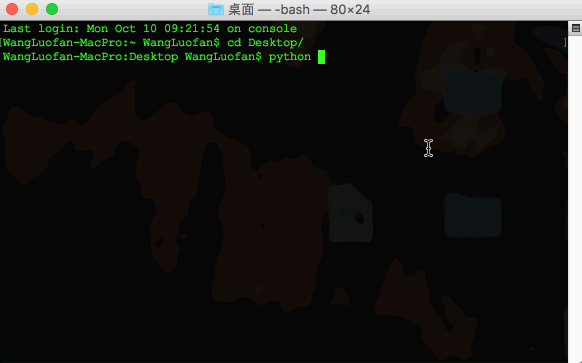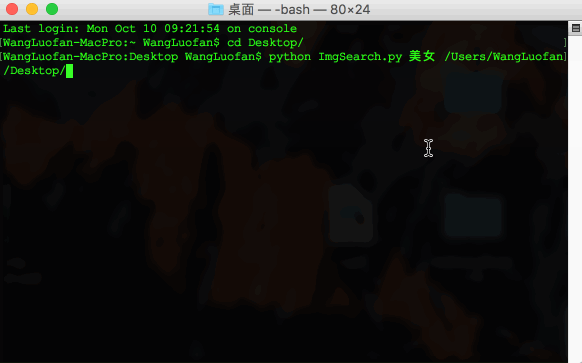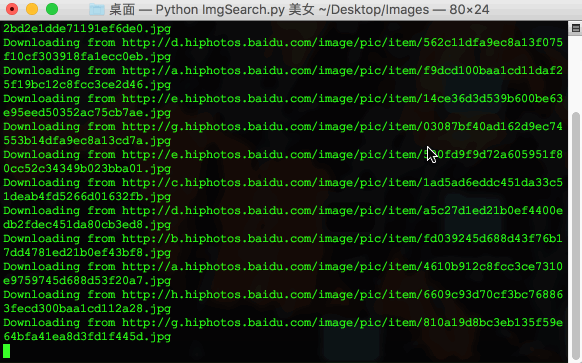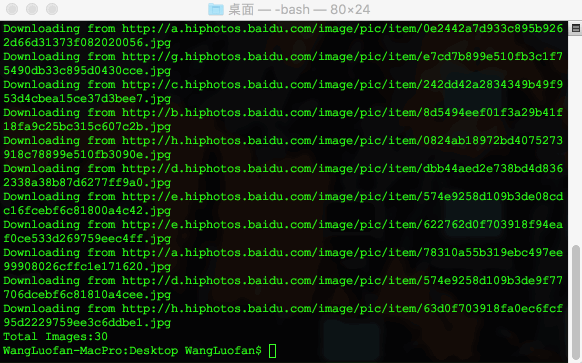
print 'Downloading from %s' % json[i]['objURL'];
Download(json[i]['objURL'], filename);
return ;使用requests库的好处就是,参数不需要连接在URL后面,只需要传入一个参数字典,并且可以使用json()方法,将返回的数据格式化到相应的数据结构中,请求到数据之后,分析JSON数据可知,其中的字段objURL,即表示了原图的下载地址。
def Download(url, filename):
if(os.path.exists(sys.argv[2]) == False):
os.mkdir(sys.argv[2]);
filepath = os.path.join(sys.argv[2], '%s' % filename);
urllib.urlretrieve(url, filepath);
return ;下载图片之前,首先要检查用户指定的下载目录存不存在,如果不存在,则需要创建目录,然后构建文件路径,使用os.path.join方法,连合两个路径,使用该方法,用户不需要添加路径分隔符。之后便可以使用urllib.urlretrieve方法下载图片了。
全部代码编写完成之后,我们便可以组织代码运行顺序,如下:
if __name__ == '__main__':
if(CheckArgs() == False):
sys.exit(-1);
Search();
print 'Total Images:%d' % file_count(sys.argv[2]);若参数输入错误,则退出脚本,否则搜索关键词,并输出相应提示。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!